AWS SageMaker: Text Classification Using Keras & TensorFlow
Overview
In this tutorial, we will use Amazon SageMaker to build, train and deploy an NLP model using custom built TensorFlow Docker containers. The NLP model will classify news articles into the appropriate news category. To train the model, we will be using the UCI News Dataset which contains a list of about 420K articles and their appropriate categories (labels). There are four categories:
- Business (b)
- Science & Technology (t)
- Entertainment (e)
- Health & Medicine (m)
Prerequisites:
Local Test:
Clone the sample code
- In JupyterLab, click the Terminal icon to open a new terminal
- To clone the tutorial repository, run the following commands
git https://github.com/lbnl-science-it/aws-sagemaker-keras-text-classification.git
cd aws-sagemaker-keras-text-classification
Training and hosting the text classifier locally (on the JupyterLab notebook instance)
cd container
sh build_docker_local_test.sh
Prediction
- Open another terminal in JupyterLab
cd container/local_test
./predict.sh input.json application/json
Data Exploration
- Navigate to
aws-sagemaker-keras-text-classificationand opensagemaker_keras_text_classification.ipynb - Execute code in JupyterLab notebook
import pandas as pd
import tensorflow as tf
import re
import numpy as np
import os
from tensorflow.python.keras.preprocessing.text import Tokenizer
from tensorflow.python.keras.preprocessing.sequence import pad_sequences
from tensorflow.python.keras.utils import to_categorical
WARNING:tensorflow:From /home/ec2-user/anaconda3/envs/tensorflow_p36/lib/python3.6/site-packages/tensorflow_core/__init__.py:1467: The name tf.estimator.inputs is deprecated. Please use tf.compat.v1.estimator.inputs instead.
column_names = ["TITLE", "URL", "PUBLISHER", "CATEGORY", "STORY", "HOSTNAME", "TIMESTAMP"]
news_dataset = pd.read_csv(os.path.join('./data', 'newsCorpora.csv'), names=column_names, header=None, delimiter='\t')
news_dataset.head()
| TITLE | URL | PUBLISHER | CATEGORY | STORY | HOSTNAME | TIMESTAMP |
|---|---|---|---|---|---|---|
| Fed official says weak data caused by weather,... | http://www.latimes.com/business/money/la-fi-mo... | Los Angeles Times | b | ddUyU0VZz0BRneMioxUPQVP6sIxvM | www.latimes.com | 1394470370698 |
news_dataset.groupby(['CATEGORY']).size()
CATEGORY
b 115967
e 152469
m 45639
t 108344
dtype: int64
Training and Hosting your Algorithm in Amazon SageMaker
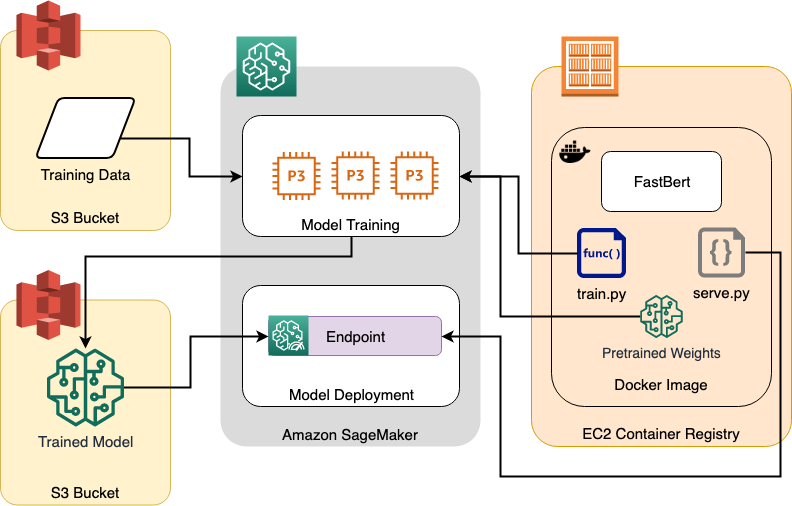
Building and registering the container
The following shell code shows how to build the container image using docker build and push the container image to ECR using docker push.
This code looks for an ECR repository in the account you're using and the current default region (if you're using a SageMaker notebook instance, this will be the region where the notebook instance was created). If the repository doesn't exist, the script will create it.
%%sh
cd container
sh build_docker.sh
Login Succeeded
Stopping docker: [ OK ]
Starting docker: .[ OK ]
Sending build context to Docker daemon 456.3MB
Step 1/9 : FROM 763104351884.dkr.ecr.us-west-2.amazonaws.com/tensorflow-training:1.14.0-cpu-py36-ubuntu16.04
---> e6a210ff54e4
Step 2/9 : RUN apt-get update && apt-get install -y nginx imagemagick graphviz
---> Using cache
---> 39d868b5172a
Step 3/9 : RUN pip install --upgrade pip
---> Using cache
---> 83610cd980fc
Step 4/9 : RUN pip install gevent gunicorn flask tensorflow_hub seqeval graphviz nltk spacy tqdm
---> Using cache
---> 090ab4fa935c
Step 5/9 : RUN python -m spacy download en_core_web_sm
---> Using cache
---> cf5c0166e852
Step 6/9 : RUN python -m spacy download en
---> Using cache
---> d39488c451a6
Step 7/9 : ENV PATH="/opt/program:${PATH}"
---> Using cache
---> 1b3759031fe0
Step 8/9 : COPY sagemaker_keras_text_classification /opt/program
---> Using cache
---> 092b378f8446
Step 9/9 : WORKDIR /opt/program
---> Using cache
---> b468053ed126
Successfully built b468053ed126
Successfully tagged sagemaker-keras-text-classification:latest
The push refers to repository [485444084140.dkr.ecr.us-west-2.amazonaws.com/sagemaker-keras-text-classification]
6738a352b9b5: Preparing
1084a39dd41b: Preparing
394cd2fefa75: Preparing
a8288ebab0e0: Preparing
a71b5abf35ed: Preparing
0ba58b74173a: Preparing
cc978a7bbd2a: Preparing
3a97a8d562fb: Preparing
cb460459ddc8: Preparing
b4064660a4cf: Preparing
b6e9883adafa: Preparing
9ee6d909e5a7: Preparing
e722e212cbab: Preparing
708ade65e147: Preparing
11fc4467b8a3: Preparing
0cf88c3675cd: Preparing
d456742927ee: Preparing
8722c9641a57: Preparing
7083756ef61f: Preparing
9d2fda619715: Preparing
e79142719515: Preparing
aeda103e78c9: Preparing
2558e637fbff: Preparing
f749b9b0fb21: Preparing
e722e212cbab: Waiting
708ade65e147: Waiting
11fc4467b8a3: Waiting
0cf88c3675cd: Waiting
d456742927ee: Waiting
8722c9641a57: Waiting
7083756ef61f: Waiting
9d2fda619715: Waiting
e79142719515: Waiting
aeda103e78c9: Waiting
2558e637fbff: Waiting
f749b9b0fb21: Waiting
0ba58b74173a: Waiting
cb460459ddc8: Waiting
cc978a7bbd2a: Waiting
3a97a8d562fb: Waiting
9ee6d909e5a7: Waiting
b6e9883adafa: Waiting
1084a39dd41b: Pushed
6738a352b9b5: Pushed
cc978a7bbd2a: Layer already exists
3a97a8d562fb: Layer already exists
cb460459ddc8: Layer already exists
394cd2fefa75: Pushed
b4064660a4cf: Layer already exists
b6e9883adafa: Layer already exists
9ee6d909e5a7: Layer already exists
a71b5abf35ed: Pushed
e722e212cbab: Layer already exists
708ade65e147: Layer already exists
0cf88c3675cd: Layer already exists
11fc4467b8a3: Layer already exists
d456742927ee: Layer already exists
7083756ef61f: Layer already exists
8722c9641a57: Layer already exists
9d2fda619715: Layer already exists
e79142719515: Layer already exists
2558e637fbff: Layer already exists
aeda103e78c9: Layer already exists
f749b9b0fb21: Layer already exists
a8288ebab0e0: Pushed
0ba58b74173a: Pushed
latest: digest: sha256:c684d06918d8e4c9ca2db9c35a663d044c89816a01df6fc34ddfd09b449c65ab size: 5344
WARNING! Using --password via the CLI is insecure. Use --password-stdin.
WARNING! Your password will be stored unencrypted in /home/ec2-user/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Once you have your container packaged, you can use it to train and serve models. Let's do that with the algorithm we made above.
Set up the environment
Here we specify a bucket to use and the role that will be used for working with SageMaker.
### S3 prefix
prefix = 'sagemaker-keras-text-classification'
### Define IAM role
import boto3
import re
import os
import numpy as np
import pandas as pd
from sagemaker import get_execution_role
role = get_execution_role()
Create the session
The session remembers our connection parameters to SageMaker. We'll use it to perform all of our SageMaker operations.
import sagemaker as sage
from time import gmtime, strftime
sess = sage.Session()
Upload the data for training
When training large models with huge amounts of data, you'll typically use big data tools, like Amazon Athena, AWS Glue, or Amazon EMR, to create your data in S3.
We can use use the tools provided by the SageMaker Python SDK to upload the data to a default bucket.
WORK_DIRECTORY = 'data'
data_location = sess.upload_data(WORK_DIRECTORY, key_prefix=prefix)
Create an estimator and fit the model
In order to use SageMaker to fit our algorithm, we'll create an Estimator that defines how to use the container to to train. This includes the configuration we need to invoke SageMaker training:
- The container name. This is constucted as in the shell commands above.
- The role. As defined above.
- The instance count which is the number of machines to use for training.
- The instance type which is the type of machine to use for training.
- The output path determines where the model artifact will be written.
- The session is the SageMaker session object that we defined above.
Then we use fit() on the estimator to train against the data that we uploaded above.
account = sess.boto_session.client('sts').get_caller_identity()['Account']
region = sess.boto_session.region_name
image = '{}.dkr.ecr.{}.amazonaws.com/sagemaker-keras-text-classification'.format(account, region)
tree = sage.estimator.Estimator(image,
role, 1, 'ml.c5.2xlarge',
output_path="s3://{}/output".format(sess.default_bucket()),
sagemaker_session=sess)
To view the progress of training: navigate to Amazon SageMaker Studio > Training > Training Jobs
tree.fit(data_location)
2020-04-22 01:18:26 Starting - Starting the training job...
2020-04-22 01:18:27 Starting - Launching requested ML instances......
2020-04-22 01:19:56 Starting - Preparing the instances for training......
2020-04-22 01:20:56 Downloading - Downloading input data
2020-04-22 01:20:56 Training - Downloading the training image......
2020-04-22 01:21:50 Training - Training image download completed. Training in progress.[34m/usr/local/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:516: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])[0m
[34m/usr/local/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:517: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])[0m
[34m/usr/local/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:518: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])[0m
[34m/usr/local/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:519: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])[0m
[34m/usr/local/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:520: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])[0m
[34m/usr/local/lib/python3.6/site-packages/tensorflow/python/framework/dtypes.py:525: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])[0m
[34m/usr/local/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint8 = np.dtype([("qint8", np.int8, 1)])[0m
[34m/usr/local/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint8 = np.dtype([("quint8", np.uint8, 1)])[0m
[34m/usr/local/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint16 = np.dtype([("qint16", np.int16, 1)])[0m
[34m/usr/local/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_quint16 = np.dtype([("quint16", np.uint16, 1)])[0m
[34m/usr/local/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
_np_qint32 = np.dtype([("qint32", np.int32, 1)])[0m
[34m/usr/local/lib/python3.6/site-packages/tensorboard/compat/tensorflow_stub/dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'.
np_resource = np.dtype([("resource", np.ubyte, 1)])[0m
[34mStarting the training.[0m
[34m TITLE ... TIMESTAMP[0m
[34m1 Fed official says weak data caused by weather,... ... 1394470370698[0m
[34m2 Fed's Charles Plosser sees high bar for change... ... 1394470371207[0m
[34m3 US open: Stocks fall after Fed official hints ... ... 1394470371550[0m
[34m4 Fed risks falling 'behind the curve', Charles ... ... 1394470371793[0m
[34m5 Fed's Plosser: Nasty Weather Has Curbed Job Gr... ... 1394470372027
[0m
[34m[5 rows x 7 columns][0m
[34mFound 65990 unique tokens.[0m
[34mShape of data tensor: (422417, 100)[0m
[34mShape of label tensor: (422417, 4)[0m
[34mx_train shape: (337933, 100)[0m
[34mWARNING: Logging before flag parsing goes to stderr.[0m
[34mW0422 01:22:22.159757 140619530934016 deprecation.py:506] From /usr/local/lib/python3.6/site-packages/tensorflow/python/keras/initializers.py:119: calling RandomUniform.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.[0m
[34mInstructions for updating:[0m
[34mCall initializer instance with the dtype argument instead of passing it to the constructor[0m
[34mW0422 01:22:22.187488 140619530934016 deprecation.py:506] From /usr/local/lib/python3.6/site-packages/tensorflow/python/ops/init_ops.py:1251: calling VarianceScaling.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.[0m
[34mInstructions for updating:[0m
[34mCall initializer instance with the dtype argument instead of passing it to the constructor[0m
[34mModel: "sequential"[0m
[34m_________________________________________________________________[0m
[34mLayer (type) Output Shape Param # [0m
[34m=================================================================[0m
[34membedding (Embedding) (None, 100, 100) 1000000 [0m
[34m_________________________________________________________________[0m
[34mflatten (Flatten) (None, 10000) 0 [0m
[34m_________________________________________________________________[0m
[34mdense (Dense) (None, 2) 20002 [0m
[34m_________________________________________________________________[0m
[34mdense_1 (Dense) (None, 4) 12 [0m
[34m=================================================================[0m
[34mTotal params: 1,020,014[0m
[34mTrainable params: 1,020,014[0m
[34mNon-trainable params: 0[0m
[34m_________________________________________________________________[0m
[34m2020-04-22 01:22:22.217855: I tensorflow/core/platform/cpu_feature_guard.cc:145] This TensorFlow binary is optimized with Intel(R) MKL-DNN to use the following CPU instructions in performance critical operations: AVX512F[0m
[34mTo enable them in non-MKL-DNN operations, rebuild TensorFlow with the appropriate compiler flags.[0m
[34m2020-04-22 01:22:22.259738: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 3000000000 Hz[0m
[34m2020-04-22 01:22:22.260199: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x23b2eb0 executing computations on platform Host. Devices:[0m
[34m2020-04-22 01:22:22.260224: I tensorflow/compiler/xla/service/service.cc:175] StreamExecutor device (0): <undefined>, <undefined>[0m
[34m2020-04-22 01:22:22.261048: I tensorflow/core/common_runtime/process_util.cc:115] Creating new thread pool with default inter op setting: 2. Tune using inter_op_parallelism_threads for best performance.[0m
[34m2020-04-22 01:22:22.291480: W tensorflow/compiler/jit/mark_for_compilation_pass.cc:1412] (One-time warning): Not using XLA:CPU for cluster because envvar TF_XLA_FLAGS=--tf_xla_cpu_global_jit was not set. If you want XLA:CPU, either set that envvar, or use experimental_jit_scope to enable XLA:CPU. To confirm that XLA is active, pass --vmodule=xla_compilation_cache=1 (as a proper command-line flag, not via TF_XLA_FLAGS) or set the envvar XLA_FLAGS=--xla_hlo_profile.[0m
[34mTrain on 337933 samples, validate on 84484 samples[0m
[34mEpoch 1/6[0m
[34m337933/337933 - 29s - loss: 0.6303 - acc: 0.7653 - val_loss: 0.5580 - val_acc: 0.7959[0m
[34mEpoch 2/6[0m
[34m337933/337933 - 29s - loss: 0.5502 - acc: 0.7977 - val_loss: 0.5558 - val_acc: 0.7955[0m
[34mEpoch 3/6[0m
[34m337933/337933 - 29s - loss: 0.5427 - acc: 0.8000 - val_loss: 0.5450 - val_acc: 0.8004[0m
[34mEpoch 4/6[0m
[34m337933/337933 - 29s - loss: 0.5391 - acc: 0.8010 - val_loss: 0.5407 - val_acc: 0.8018[0m
[34mEpoch 5/6[0m
[34m337933/337933 - 29s - loss: 0.5363 - acc: 0.8022 - val_loss: 0.5403 - val_acc: 0.8035[0m
[34mEpoch 6/6[0m
2020-04-22 01:25:23 Uploading - Uploading generated training model
2020-04-22 01:25:23 Completed - Training job completed
[34m337933/337933 - 29s - loss: 0.5342 - acc: 0.8032 - val_loss: 0.5424 - val_acc: 0.8014[0m
[34mTraining complete. Now saving model to: /opt/ml/model[0m
[34mW0422 01:25:15.442514 140619530934016 deprecation.py:506] From /usr/local/lib/python3.6/site-packages/tensorflow/python/ops/init_ops.py:97: calling GlorotUniform.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.[0m
[34mInstructions for updating:[0m
[34mCall initializer instance with the dtype argument instead of passing it to the constructor[0m
[34mW0422 01:25:15.442924 140619530934016 deprecation.py:506] From /usr/local/lib/python3.6/site-packages/tensorflow/python/ops/init_ops.py:97: calling Zeros.__init__ (from tensorflow.python.ops.init_ops) with dtype is deprecated and will be removed in a future version.[0m
[34mInstructions for updating:[0m
[34mCall initializer instance with the dtype argument instead of passing it to the constructor[0m
[34mTest headline: What Improved Tech Means for Electric, Self-Driving and Flying Cars[0m
[34mPredicted category: b[0m
Training seconds: 283
Billable seconds: 283
Deploy the model
Deploying the model to SageMaker hosting just requires a deploy call on the fitted model. This call takes an instance count, instance type, and optionally serializer and deserializer functions. These are used when the resulting predictor is created on the endpoint.
This step may take about 10-20 min
from sagemaker.predictor import json_serializer
predictor = tree.deploy(1, 'ml.m4.xlarge', serializer=json_serializer)
-------------!
Prediction
request = { "input": "‘Deadpool 2’ Has More Swearing, Slicing and Dicing from Ryan Reynolds"}
print(predictor.predict(request).decode('utf-8'))
{"result": "Entertainment"}
Endpoint Test
To view the endpoint_name you just deployed: navigate to Amazon SageMaker Studio > Inference > Endpoints
InvokeEndpoint using boto3
import json
import boto3
client = boto3.client('runtime.sagemaker')
endpoint_name = 'sagemaker-keras-text-classification-2020-04-22-01-18-26-512'
payload = { "input": "‘Deadpool 2’ Has More Swearing, Slicing and Dicing from Ryan Reynolds"}
response = client.invoke_endpoint(EndpointName=endpoint_name,
ContentType='application/json',
Accept='text/plain',
Body=json.dumps(payload))
response_body = response['Body']
prediction = response_body.read().decode('utf-8')
print(prediction)
{"result": "Entertainment"}
InvokeEndpoint using AWS CLI
%%sh
ENDPOINT_NAME="sagemaker-keras-text-classification-2020-04-22-01-18-26-512"
CONTENT_TYPE='application/json'
aws sagemaker-runtime invoke-endpoint \
--endpoint-name ${ENDPOINT_NAME} \
--content-type ${CONTENT_TYPE} \
--body '{"input": "Why Exercise Alone May Not Be the Key to Weight Loss"}' prediction_response.json
cat prediction_response.json
{
"ContentType": "application/json",
"InvokedProductionVariant": "AllTraffic"
}
{"result": "Health & Medicine"}
Optional cleanup
When you're done with the endpoint, you'll want to clean it up.
sess.delete_endpoint(predictor.endpoint)
References
- https://github.com/aws-samples/amazon-sagemaker-keras-text-classification
- https://github.com/lbnl-science-it/aws-sagemaker-keras-text-classification
- https://docs.aws.amazon.com/sagemaker/latest/dg/notebooks.html